Real-time object detection has become a cornerstone in the development of advanced vision-powered systems. These systems rely on the ability to rapidly detect and localize objects within images or video streams.
Earlier approaches to object detection, such as Faster R-CNN, required multiple stages. These models often struggled in real-time applications due to their slower processing times.
Enter YOLO (You Only Look Once). The YOLO series of models perform object detection in a single pass, directly predicting bounding boxes and class probabilities in real-time. YOLO models have made real-time object detection possible with lower computational resources, without significantly compromising accuracy, making them a go-to tool in AI-driven applications.
In this article, we take a deep dive into the different YOLO models and explore how each has improved upon its predecessor. We will also discuss how a modern Vision AI system like Awareye utilizes these models to bring large-scale, multi-camera vision AI to enterprises, helping them with process mining and streamlining their operations.
Let’s dive in!
Architecture of YOLO Models
YOLO's single-shot detection mechanism, as is evident from the name (‘you only look once’), looks at the entire image only once, performing both object classification and localization in one go.
Compared to two-stage models like Faster R-CNN, YOLO’s streamlined detection process boosts its speed at the cost of slightly lower accuracy, particularly in complex scenarios involving small or overlapping objects. However, for real-time applications, this trade-off is often worthwhile.
YOLO’s architecture also benefits from anchor boxes and feature pyramid networks in later versions, improving upon its ability to detect objects at multiple scales, making it more versatile for different detection tasks while retaining high efficiency.
Grid-Based Object Detection
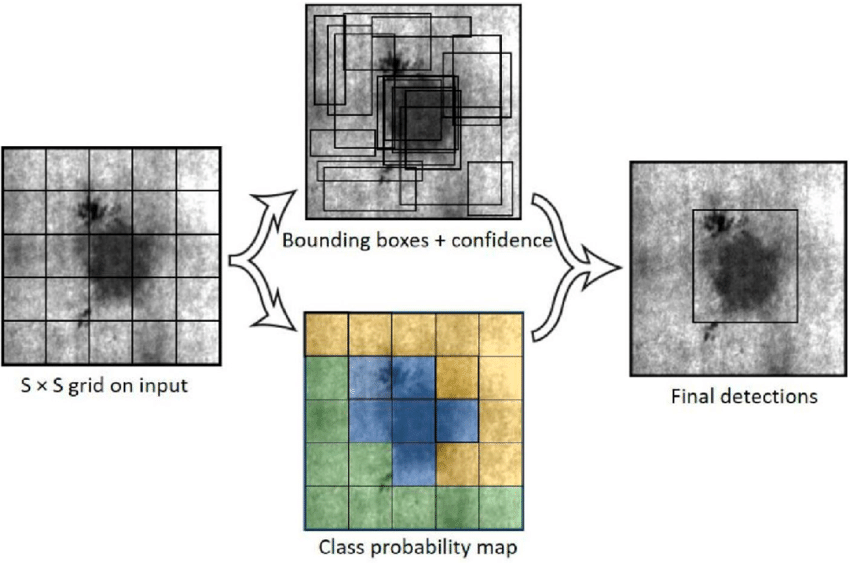
To explain it simply, YOLO’s architecture divides the input image into an S×S grid, with each grid cell responsible for predicting the presence of an object if its center lies within that cell. For each grid cell, the YOLO model predicts several bounding boxes and the corresponding confidence score, indicating how likely it is that a box contains an object.
Additionally, YOLO predicts the class probabilities for each bounding box, which allows it to determine what kind of object is detected. This system enables the model to detect multiple objects in various locations within an image simultaneously, without requiring multiple stages.
Neural Networks for Feature Extraction
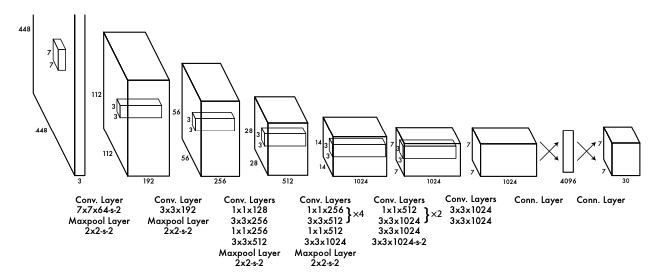
To process visual features, YOLO models use convolutional neural networks (CNNs). Earlier versions like YOLOv1 relied on simpler backbones, but later iterations, such as YOLOv3, incorporated more advanced feature extraction networks like Darknet, improving the model’s ability to handle diverse object scales.
With the more recent YOLO versions, such as YOLOv5 and YOLOv8, the size of the neural network varies based on the model variant. YOLOv5, for instance, is available in five sizes: nano (n), small (s), medium (m), large (l), and extra-large (x). These models range from around 1.9 million parameters for YOLOv5-nano to 87 million parameters for YOLOv5-extra-large, allowing for a flexible trade-off between speed and accuracy depending on the task.
YOLOv8 also follows a similar scaling approach, optimizing both speed and performance, with larger models capable of handling more complex tasks while maintaining real-time capabilities.
Loss Function and Non-Max Suppression (NMS)
YOLO models use a custom loss function that optimizes three key aspects simultaneously: classification, localization, and objectness. The classification loss ensures that the model correctly identifies the objects in each bounding box. Localization loss is used to fine-tune the predicted bounding boxes to align as closely as possible with the ground-truth coordinates. Objectness loss ensures the model accurately predicts whether a box contains an object or not.
To address the issue of overlapping predictions, Non-Max Suppression (NMS) is applied during post-processing. NMS eliminates redundant bounding boxes that detect the same object multiple times by selecting only the bounding box with the highest confidence score while suppressing others with lower confidence but a high overlap (measured by IoU—Intersection over Union). This step ensures that only the best bounding boxes for each object are retained.
Single-Shot Object Detection
One of YOLO’s defining features is its ability to process an image in a single forward pass. Unlike two-stage models like Faster R-CNN, which first generates region proposals and then classifies them, YOLO combines these steps into one.
YOLO divides the image into a grid, as discussed above, and predicts bounding boxes and class probabilities for each grid cell in a single step. This approach allows YOLO to process multiple frames per second, achieving real-time object detection by reducing the complexity and the number of operations required per image.
As a result, YOLO is extremely fast, making it ideal for real-time applications like video analysis. At Awareye, we select the appropriate YOLO model based on the specific problem at hand, leveraging its real-time capabilities.
Multi-Scale Detection
In object detection, detecting objects of varying sizes is essential to achieve high accuracy. YOLO models excel at multi-scale detection by leveraging multi-resolution feature maps. Specifically, YOLO extracts features from different layers of the neural network, where each layer captures information at varying scales. Lower layers focus on smaller details (useful for detecting smaller objects), while deeper layers capture broader context (helpful for larger objects). By combining these multi-scale features, YOLO ensures that objects of different sizes are accurately detected within a single image.
YOLOv3 and YOLOv4 refine this further by using Feature Pyramid Network (FPN) and Path Aggregation Network (PANet) to enhance feature reuse across scales. This allows YOLO to effectively balance the detection of both small objects, like faces or helmets, and large objects, like containers, in the same image, making it highly versatile for vision applications in industrial environments.
Evolution of YOLO: From YOLOv1 to YOLOv10
Now that we understand the architecture of YOLO models, let’s look at how they have evolved.
The first version, YOLOv1, introduced in 2015, was groundbreaking for its single-shot detection mechanism, but it struggled with smaller objects and overlapping detections. YOLOv1 divided the image into a fixed grid and predicted two bounding boxes per grid cell, which limited its ability to handle complex scenes.
As the versions progressed, significant improvements were made. By YOLOv3, the model began leveraging Darknet-53, a deeper and more powerful backbone with 53 convolutional layers, significantly improving feature extraction over YOLOv1. It also introduced multi-scale predictions, allowing it to better detect objects of varying sizes. YOLOv4 brought further optimization with Cross-Stage Partial Networks (CSPNet) and Spatial Pyramid Pooling (SPP), improving speed and accuracy for small and large objects alike.
YOLOv8, built on these advancements, introduced features like anchor-free detection and Neural Architecture Search (NAS), making the model even more adaptive and efficient. YOLOv8 also enhanced real-time performance and accuracy, particularly in complex, dynamic environments.
YOLOv9 (released in early 2024) introduced Programmable Gradient Information (PGI) and GELAN to improve training efficiency and feature aggregation, offering faster and more accurate object detection without increasing computational costs. These innovations enhance its performance in real-time tasks.
YOLOv10 (released in May 2024) builds on these advancements with a dual-pathway system that eliminates Non-Maximum Suppression (NMS) during inference, improving both speed and accuracy. YOLOv10 also introduces large-kernel convolutions and partial self-attention, making it highly efficient for dynamic, real-time applications like autonomous driving and industrial automation
YOLOv10 is the most cutting-edge YOLO model for now and is being extensively used for real-time end-to-end object detection tasks.
YOLOv1: The Beginning
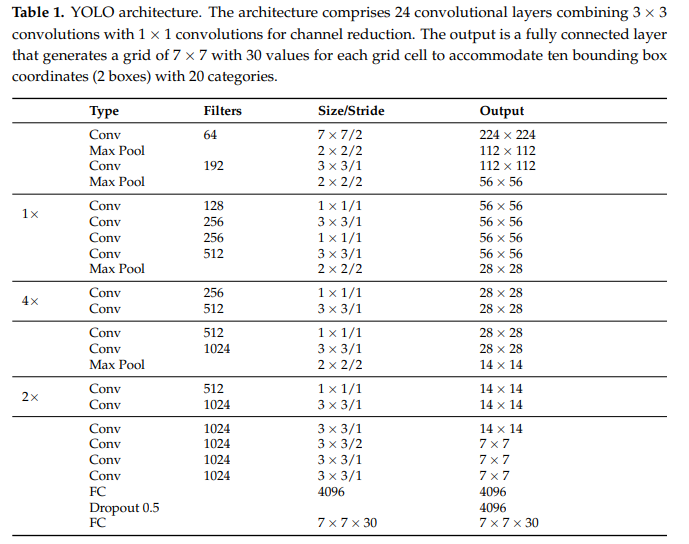
The original YOLOv1 simplified object detection into a single-stage model, capable of processing images in real-time. However, it struggled with detecting small objects and lacked fine-grained localization capabilities, leading to significant limitations in more detailed detection tasks.
YOLOv2 and YOLO9000
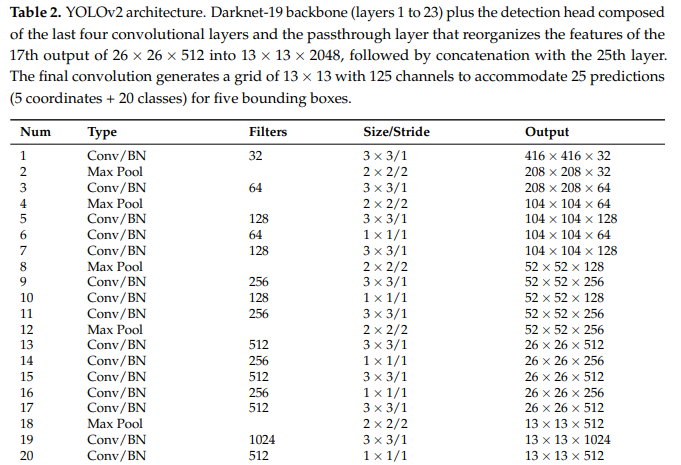
YOLOv2 introduced key enhancements, including batch normalization, higher-resolution images, and the use of anchor boxes for better localization. YOLO9000 built upon this by introducing the WordTree, allowing detection of over 9,000 object categories.
YOLOv3: Feature Pyramid Network for Multi-Scale Detection
YOLOv3 incorporated a Feature Pyramid Network (FPN), enabling the detection of objects at multiple scales. This model could detect objects at small, medium, and large levels, significantly improving accuracy over earlier versions.
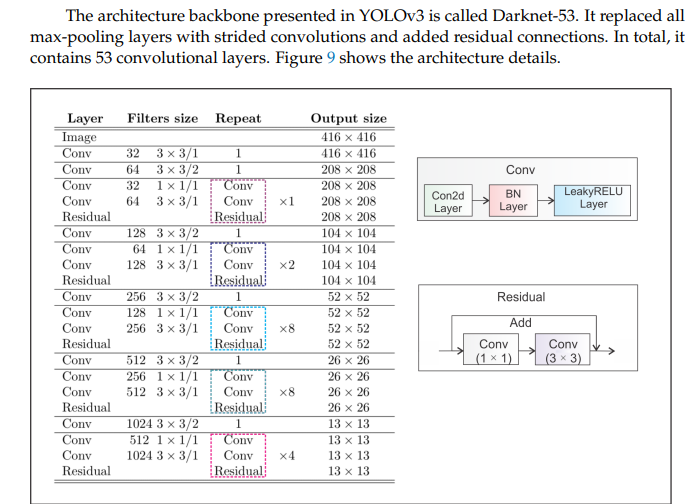
YOLOv4: Real-Time Speed with State-of-the-Art Accuracy
With YOLOv4, real-time object detection reached new heights. Innovations such as the CSPDarknet53 backbone, mosaic data augmentation, and the Spatial Pyramid Pooling (SPP) module improved speed and accuracy. Techniques like PANet and CIoU loss further refined the model’s performance.
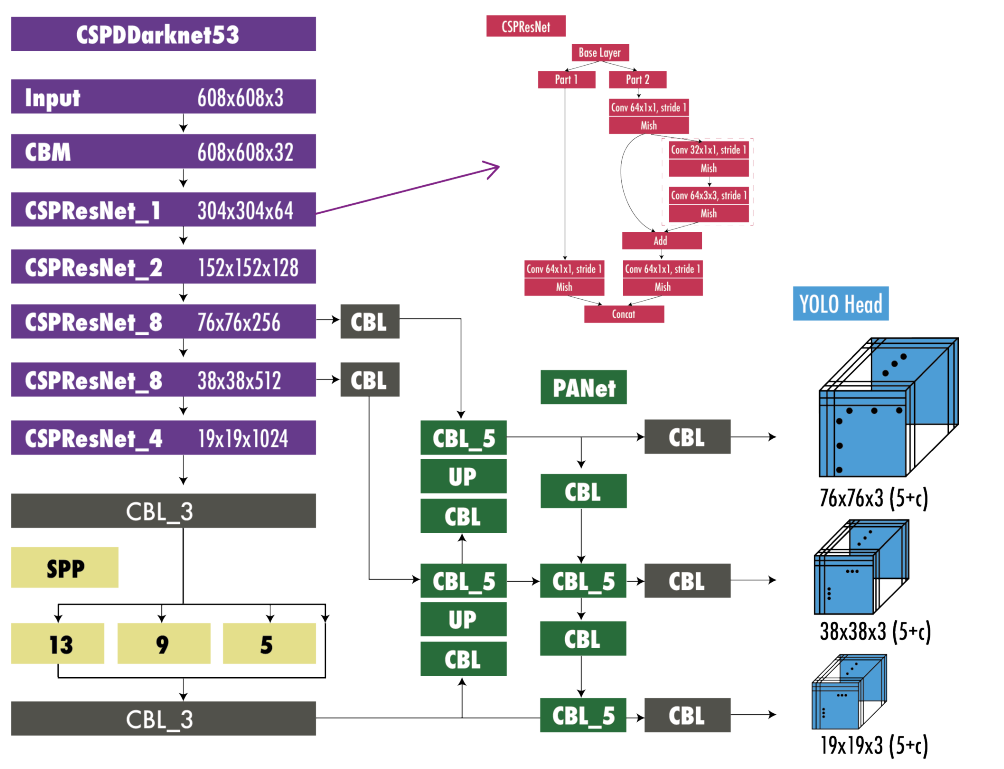
YOLOv5: Python Implementation
YOLOv5 marked a significant transition by moving to the PyTorch framework, making it easier to train, deploy, and customize models. Its user-friendly design made it popular among developers working on custom object detection tasks.
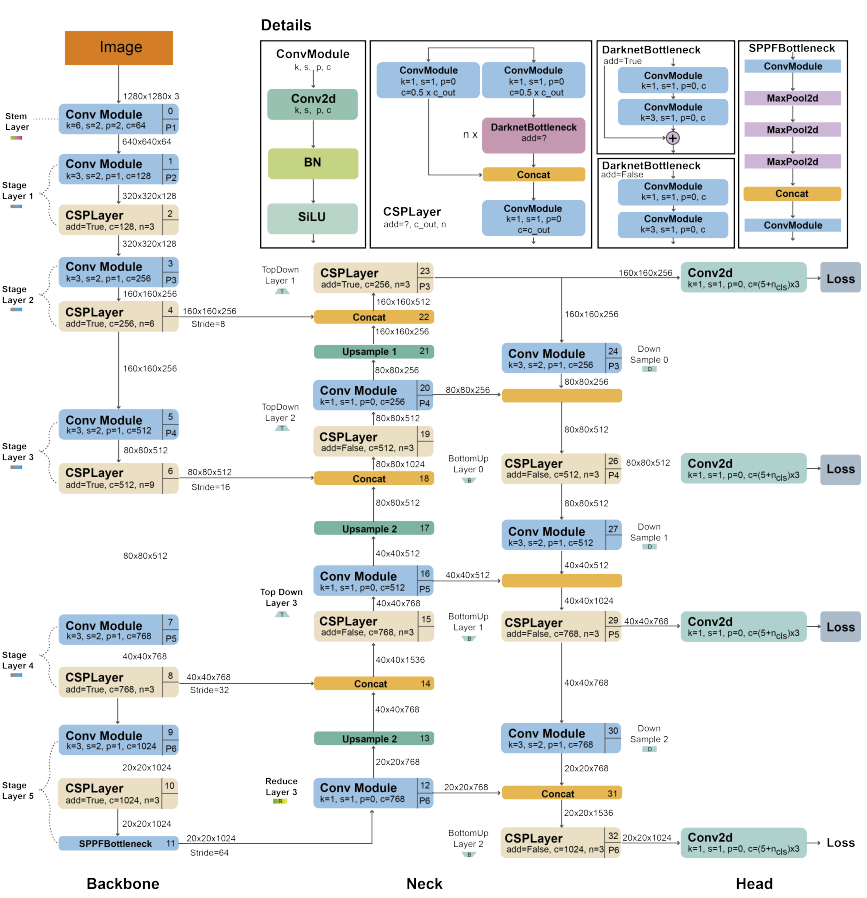
YOLOv8: Advancements in Speed and Accuracy
YOLOv8 introduces significant improvements over its predecessors, including the CSPDarknet53 backbone for better feature extraction and PANet for enhanced multi-scale detection. It also employs dynamic anchor assignment and advanced data augmentation techniques like MixUp to improve generalization.
The training process is optimized with mixed-precision training, leading to faster convergence without sacrificing accuracy. These updates make YOLOv8 both highly accurate and efficient, suitable for real-time applications across various industrial settings.
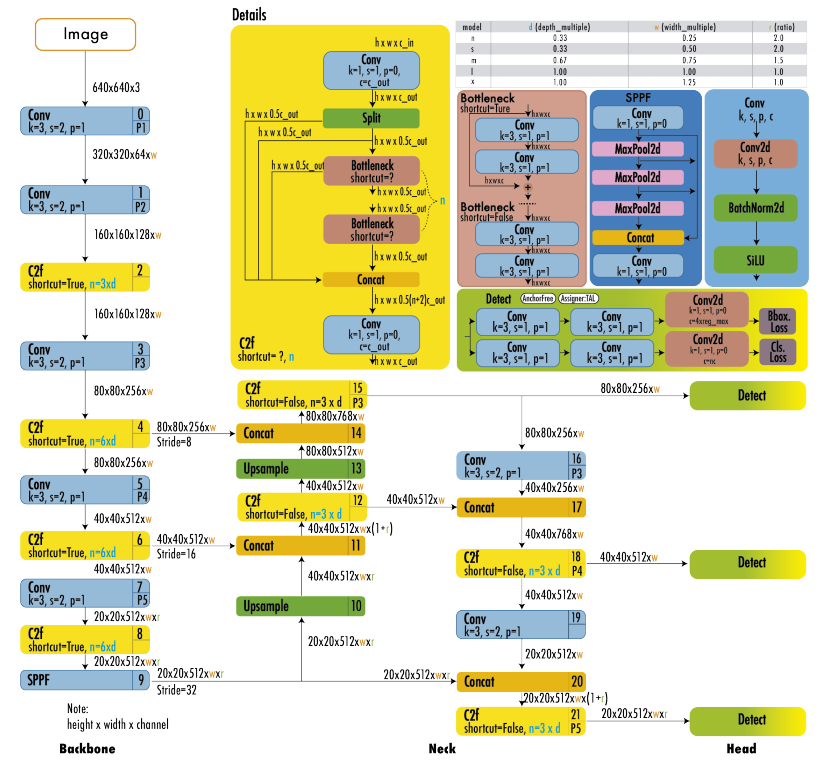
YOLOv9: Learning What You Want to Learn
YOLOv9 introduced features like Programmable Gradient Information (PGI) and the Generalized Efficient Layer Aggregation Network (GELAN).
PGI addresses the information bottleneck in deep networks, improving training efficiency and gradient propagation, while GELAN optimizes multi-scale feature aggregation.
These enhancements make YOLOv9 highly efficient in balancing speed and accuracy, offering superior performance in real-time object detection tasks without significant computational overhead.
YOLOv10: Real-Time End-to-End Object Detection
YOLOv10, launched shortly after in May 2024, takes these advancements even further by introducing a dual-pathway approach that combines both one-to-one and one-to-many matching strategies for label assignments. This allows YOLOv10 to eliminate the need for Non-Maximum Suppression (NMS) during inference, improving both efficiency and accuracy.
The model also features architectural refinements like large-kernel convolutions and partial self-attention modules, which enhance its feature extraction capabilities. YOLOv10 demonstrates improved speed and accuracy compared to YOLOv9, making it ideal for dynamic, real-time applications such as autonomous driving and industrial automation.
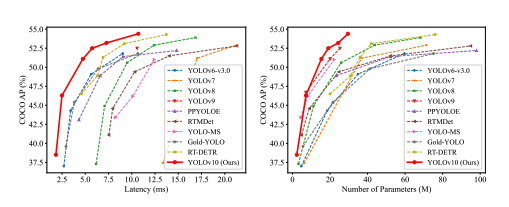
At the time of writing this, YOLOv10 is the latest publicly available model, widely used for a range of real-time object detection and tracking applications. The model comes in several variants, each optimized for different use cases and hardware constraints.
These variants include:
- YOLOv10-N (Nano): Lightweight, optimized for edge devices, offering a balance between speed and accuracy.
- YOLOv10-S (Small): Suitable for mid-level tasks with higher accuracy than Nano, while still being efficient.
- YOLOv10-M (Medium): Offers improved accuracy with more parameters, designed for larger, more complex tasks.
- YOLOv10-L (Large): Optimized for tasks requiring higher precision, with a greater computational load.
- YOLOv10-X (Extra-Large): The most powerful variant, providing the highest accuracy, suited for demanding real-time applications.
Training YOLO Models for Custom Object Detection
The key thing to note is that each of the YOLO models can be fine-tuned or trained on specific object detection tasks.
Below is an outline of the training process.
Training YOLO Models
To train YOLO models, you generally have to follow a few key steps:
- Dataset Preparation: The first step is to gather a labeled dataset of images. For custom object detection or tracking tasks, you need to create the dataset manually. This applies especially to scenarios where you are planning to use YOLO models on factory floors, for process mining, or smart operations.
- Model Configuration: You need to configure YOLOv10 models by providing values for input resolution, number of epochs, and batch size. You can also define anchor boxes or go anchor-free, depending on the complexity of objects and applications. Configuring it correctly is key to making the model work well.
- Data Augmentation: YOLO models rely on various data augmentation techniques like Mosaic augmentation, MixUp, and HSV augmentation to improve model generalization and robustness. This helps the model perform better in real-world scenarios where object appearance may vary. You should ideally perform data augmentation before the training step described below.
- Training: YOLOv10 training typically takes place over hundreds of epochs, with frequent checkpoints to assess model performance, and it is done on high-end GPUs, like H200, H100, or A100 for large datasets.
- Evaluation: After training, the model is evaluated using metrics such as mAP (mean Average Precision) at different IoU thresholds to measure its precision and recall across various object categories. You can also evaluate it on the actual setting where you would be using the model, and track its performance on the tasks.
- Deployment: Once trained, YOLOv10 models can be deployed on a wide range of devices, from cloud servers to edge devices. In industrial settings, or for enterprise applications, we recommend coupling the model with DeepStream SDK, and then containerizing it, so that you can scale the number of camera feeds it can process based on your workload.
Typically, you need to train the model and then adapt it over time to ensure it can handle edge cases not included in the training dataset. When using the model with platforms like Awareye, the trained model can be incrementally updated over time with zero disruption.
The process of training the model is fairly simple. Here’s a short explanation of the actual code steps.
Step 1: Clone the YOLOv10 model in your training server
To train the model, you first need to clone the model in the GPU server you are going to use. The size of the model, the dataset and the number of epochs should define your GPU choice.
Get the model from the official GitHub repository.
!pip install -q git+https://github.com/THU-MIG/yolov10.gitStep 2: Download the right variant
Next, we will create a directory and download the right variant of the model.
!mkdir -p {HOME}/weights
!wget -P {HOME}/weights -q https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10l.pt
!ls -lh {HOME}/weightsStep 3: Training
Finally, assuming you have your training data in a yaml file, you can train in the following way:
!yolo task=detect mode=train epochs=1000 batch=16 plots=True \
model=/weights/yolov10l.pt \
data=/data.yamlThat’s all.
Step 4: Model Deployment
To deploy the model, the recommended approach is to use DeepStream SDK. DeepStream allows you to deploy high-performance, real-time solutions for object detection, classification, and tracking using GPUs. DeepStream is optimized for Nvidia hardware and supports a wide range of AI models, including all the YOLO models.
The SDK is particularly useful for tasks involving multiple camera feeds, such as smart cities, retail analytics, or autonomous driving. It integrates well with Nvidia’s TensorRT and CUDA libraries, ensuring that applications can process video streams with low latency and high throughput, making it ideal for real-time use cases.
Here’s a high level overview of the steps that are involved in deploying YOLOv10 with DeepStream SDk.
- Install DeepStream SDK: Download and install the DeepStream SDK from NVIDIA’s website. Make sure you have compatible Nvidia GPUs and the required drivers (CUDA, TensorRT).
- Set Up the YOLO Model: Choose the appropriate YOLO version (such as YOLOv10) and export it in ONNX format, as DeepStream supports ONNX models for efficient processing. Make sure to configure the model with the right input size and anchor boxes. This is key.
- Configure DeepStream Pipeline: Modify the DeepStream configuration files (config_infer_primary_yolo.txt) to integrate the YOLO model. For this, you need to set the paths to the ONNX model, specify input/output layers, and set batch size and other processing parameters.
- Use Gst-nvinfer Plugin: DeepStream uses the gst-nvinfer plugin to perform inference on video frames. Ensure this plugin is configured in the GStreamer pipeline to handle the model inference.
- Optimize with TensorRT: DeepStream optimizes models with Nvidia TensorRT. Enable precision settings such as FP16 or INT8 for faster inference without compromising too much on accuracy.
- Deploy and Run the Pipeline: Once configured, run the GStreamer pipeline with the DeepStream SDK to process live video streams or recorded footage. You can integrate it into applications for video analytics, such as smart surveillance or object detection.
- Monitor and Tune: Optimize performance by adjusting configuration parameters, such as batch size, precision, and frame rates, to ensure smooth deployment based on your hardware capabilities.
How Awareye Simplifies Deployment of YOLO Models at Scale
Awareye simplifies the deployment and maintenance of cutting-edge object detection models like YOLOv10 for enterprises. The Awareye platform is built on containerized versions of NVIDIA’s DeepStream SDK, allowing enterprises to easily deploy, scale, and manage YOLO models across their infrastructure without requiring specialized AI knowledge.
Here's how Awareye simplifies this process:
- Containerization and Scalability: By leveraging containerized environments, Awareye ensures that models like YOLOv8 can be deployed easily and scaled as required. This means you can scale your object detection systems effortlessly — especially when using on-premise hardware, which is typically the case with multi-camera setups.
- Streamlined Model Updates and Retraining: Once Awareye on-premise is installed, enterprises can easily update or retrain their YOLO models without needing to upgrade their servers or overhaul their systems. Awareye allows for seamless integration of model updates, ensuring that new versions of YOLO or retrained models can be deployed without needing any intervention from your team. This means that you can use the most cutting-edge vision models as they are released.
- Optimized for Real-Time Performance: By using DeepStream SDK, Awareye ensures that YOLO models can process high-resolution video streams in real time, with minimal latency. Awareye’s integration of GPU-accelerated pipelines allows for high-performance object detection, even when processing thousands of camera feeds simultaneously. This is crucial for applications that require real-time analytics, such as in logistics, manufacturing, and surveillance.
- Scaling Across Thousands of Cameras: Awareye is built to scale across thousands of commodity cameras, dramatically driving down the cost of setup. Traditional high-performance AI systems often require expensive, specialized cameras, each of which might cost anywhere between $5K to $10K. However, with Awareye’s solution, enterprises can use affordable, off-the-shelf camera systems while still achieving high-quality object detection. We have a list of cameras that work with our platform and are capable of generating high-quality RTSP video streams.
Conclusion
To summarize, if you are looking to use YOLO models in your enterprise applications, Awareye provides a solution that works at scale. We simplify the management and deployment process of vision models while ensuring that you can continually update and refine the models without the need for server upgrades.
Ready to revolutionize your object detection workflow? Schedule a demo with Awareye today to discover how our platform can streamline your AI-driven operations, reduce costs, and scale effortlessly to meet your enterprise needs.




